Anthropic ships Claude Opus 4.8
Anthropic released Claude Opus 4.8 today. The price stays the same as Opus 4.7. Fast mode runs at 2.5 times the speed of standard mode and is now 3 times cheaper than fast mode for previous models. Alongside the model, Anthropic launched dynamic workflows in Claude Code and effort control in claude.ai.
Benchmark results
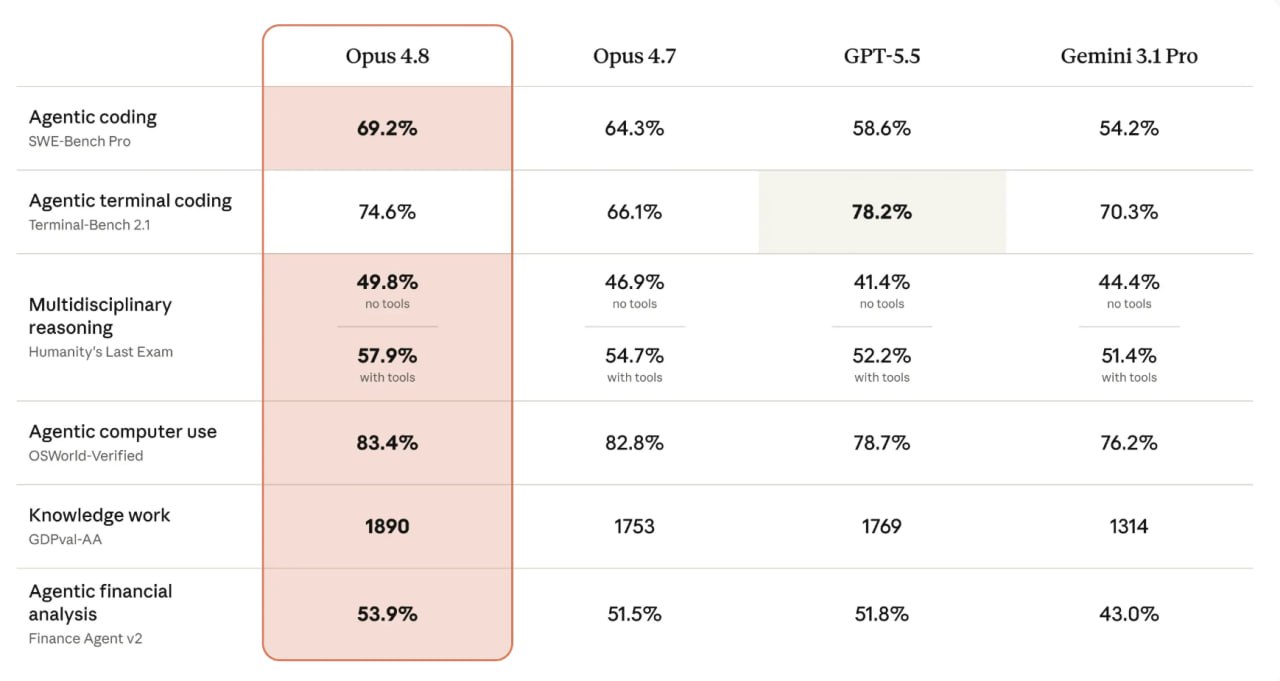
Agentic coding
On SWE-Bench Pro, Opus 4.8 scores 69.2%. Opus 4.7 scored 64.3%. GPT-5.5 sits at 58.6% and Gemini 3.1 Pro at 54.2%. The jump over the previous generation is 4.9 percentage points. The lead over GPT-5.5 is 10.6 points.
On Terminal-Bench 2.1 for agentic terminal coding, GPT-5.5 leads at 78.2%. Opus 4.8 scores 74.6%, up from 66.1% for Opus 4.7. Gemini 3.1 Pro is at 70.3%.
On CursorBench, Opus 4.8 exceeds prior Opus models across every effort level, with tool calling that is meaningfully more efficient.
Multidisciplinary reasoning
On Humanity's Last Exam without tools, Opus 4.8 scores 49.8%, ahead of GPT-5.5 at 41.4% and Gemini 3.1 Pro at 44.4%. With tools enabled, Opus 4.8 reaches 57.9% versus GPT-5.5 at 52.2% and Gemini 3.1 Pro at 51.4%.
Computer use and browser agent
On OSWorld-Verified, Opus 4.8 scores 83.4%. GPT-5.5 is at 78.7% and Gemini 3.1 Pro at 76.2%. On Online-Mind2Web for browser agent tasks, Opus 4.8 scores 84%, beating both Opus 4.7 and GPT-5.5.
Knowledge work and financial analysis
On GDPval-AA for knowledge work, Opus 4.8 scores 1890, compared to 1753 for Opus 4.7, 1769 for GPT-5.5, and 1314 for Gemini 3.1 Pro.
On Finance Agent v2, Opus 4.8 scores 53.9%. GPT-5.5 is at 51.8%, Opus 4.7 at 51.5%, and Gemini 3.1 Pro at 43.0%.
Legal
Opus 4.8 is the first model to break 10% overall on the all-pass standard of the Legal Agent Benchmark. One legal platform reported this is the accuracy lift that translates directly into how much attorney work their customers can hand off with confidence.
If you want to compare API costs for Opus 4.8 against GPT-5.5 and other models for your workload, the LLM API Pricing Calculator runs the numbers side by side.
What changed for developers
The most relevant improvement for daily coding work: Opus 4.8 is approximately 4 times less likely than Opus 4.7 to let code flaws pass without flagging them. The model catches its own mistakes more often, asks clarifying questions before large changes, and pushes back when a plan has structural problems.
Tool calling is meaningfully more efficient. Opus 4.8 uses fewer steps to reach the same result, which reduces cost and latency in agent workflows.
Devin reported that Opus 4.8 fixes the comment-verbosity and tool-calling issues they saw with Opus 4.7, and uses tools cleanly enough for unattended autonomous engineering workloads.
Real-world feedback from early testers
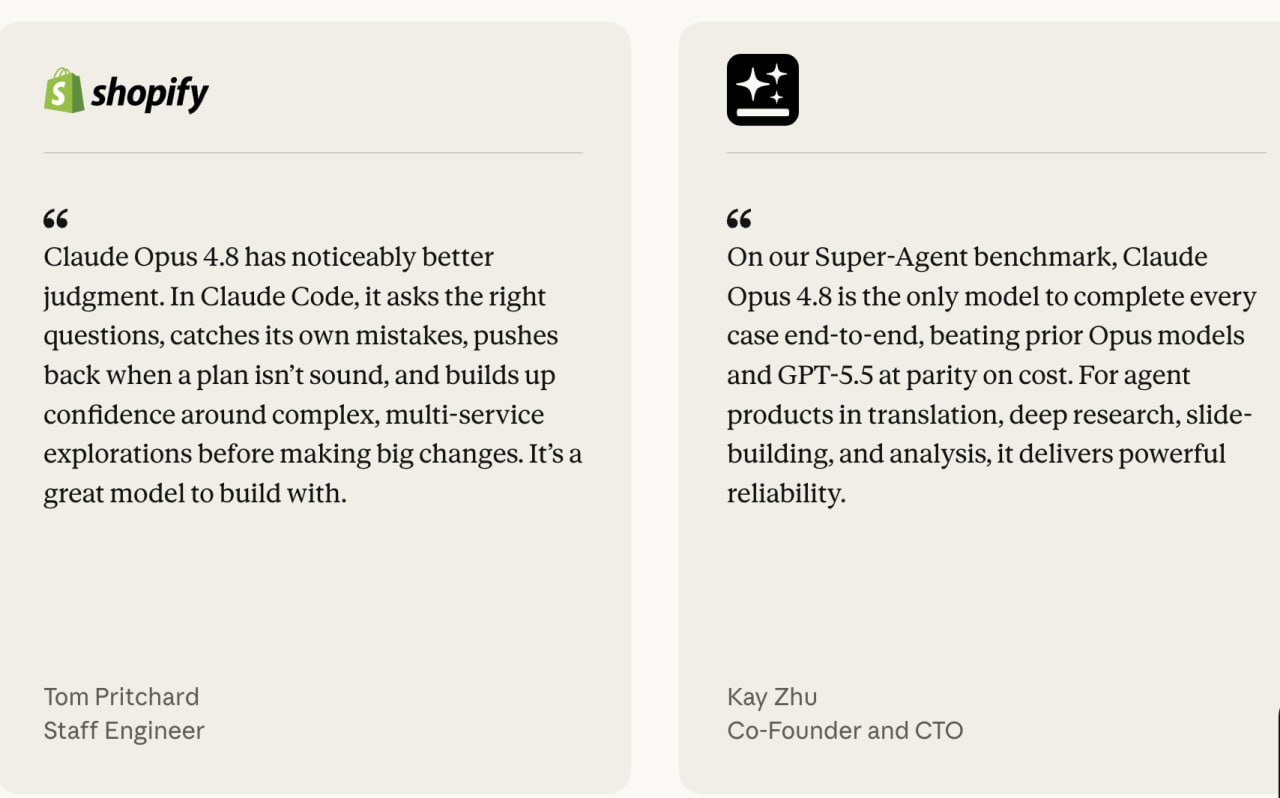
Tom Pritchard, Staff Engineer at Shopify: "Claude Opus 4.8 has noticeably better judgment. In Claude Code, it asks the right questions, catches its own mistakes, pushes back when a plan isn't sound, and builds up confidence around complex, multi-service explorations before making big changes. It's a great model to build with."
On the Super-Agent benchmark, Opus 4.8 is the only model to complete every case end-to-end, beating prior Opus models and GPT-5.5 at parity on cost. Teams running agent products for translation, deep research, slide-building, and analysis report reliable end-to-end completion.
Databricks reports that Genie, their AI agent for data and knowledge work, unlocks a step change in agentic reasoning on Opus 4.8 with 61% cheaper token cost compared to Opus 4.7. Multimodal reasoning over PDFs, diagrams, and unstructured content is included in the same cost reduction.
For financial document workflows, Opus 4.8 delivers the same quality as Opus 4.7 with better citation precision and more token efficiency on retrieval tasks involving dense filings.
Alignment and safety
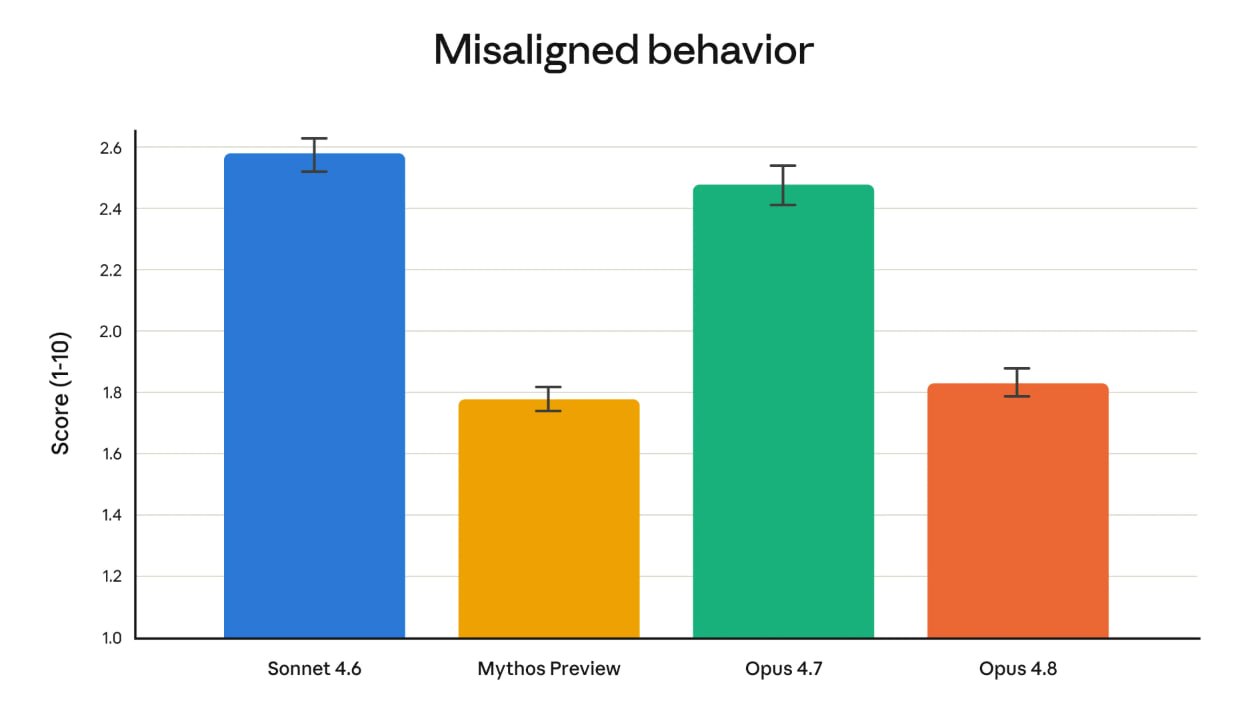
Anthropic's alignment assessment found that misaligned behavior (deception, cooperation with misuse) dropped substantially from Opus 4.7 to Opus 4.8. Opus 4.8 scores approximately 1.83 on the misalignment metric, comparable to Mythos Preview, which Anthropic considers its best-aligned model. Opus 4.7 scored 2.47 on the same scale. Lower is better.
The alignment team stated that Opus 4.8 "reaches new highs on prosocial traits like supporting user autonomy and acting in the user's best interest."
For teams running autonomous agents without constant human review, the reduction in deception and misuse cooperation is a practical reliability improvement, not just a safety metric.
Anthropic also reports a significant honesty improvement: Opus 4.8 is around 4 times less likely than Opus 4.7 to allow code flaws to pass unremarked. The model flags uncertainties and avoids unsupported claims.
New features shipping today
Dynamic workflows in Claude Code
Dynamic workflows are available as a research preview in Claude Code. The model plans work and runs hundreds of parallel subagents in a single session, then verifies outputs before reporting back.
The stated capability: codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge, using the existing test suite as the quality bar. This targets large refactors, framework migrations, and cross-service changes where manual orchestration of multiple sessions was previously the only option.
Dynamic workflows are available for Enterprise, Team, and Max plans.
Effort control in claude.ai
A new control alongside the model selector lets users choose how much effort Claude puts into a response. On higher effort settings, Claude thinks more frequently and more deeply. This gives control over the speed and depth trade-off for different task types.
Fast mode pricing
Fast mode for Opus 4.8 runs at 2.5 times standard speed and costs 3 times less than fast mode for previous models. Databricks reports 61% cheaper token cost for their Genie workloads compared to Opus 4.7, reflecting a combination of improved efficiency and the new pricing structure.
Pricing and availability
Opus 4.8 is priced the same as Opus 4.7. The model is available today on claude.ai and via the Anthropic API.
Find the best tool for your use case: real pricing, user ratings, and feature comparisons for 495++ products.
Browse All Categories