Why are you still reading benchmark leaderboards?
Every quarter, a new model tops the MMLU chart. Engineering Twitter loses its collective mind. Your CEO forwards the TechCrunch article. And somewhere in your production stack, a model you chose eighteen months ago continues to quietly do its job - processing 2.3 million requests per day, costing you $47K monthly, woven into 35 different prompts that took your team four months to tune.
TL;DR:
- Full prompt migration between LLM providers costs $30K-80K in engineering time; re-embedding 10M documents adds $3K-8K in API fees.
- TTFT and total generation time pull in opposite directions; flagship models regularly hit 2-4s TTFT vs. sub-300ms for smaller models.
- Maintain prompt compatibility across at least two providers from day one using LiteLLM or OpenRouter as an abstraction layer.
The benchmark obsession is the single most expensive distraction in enterprise AI right now. Not because benchmarks are useless - they measure something real. But because the gap between "scores well on graduate-level reasoning tasks" and "reliably extracts invoice line items at 200ms P99 for $0.003 per call" is a gap that has bankrupted more AI projects than any technical limitation.
The pattern is always the same: teams chose based on benchmarks, discovered the real constraints too late, and now face a migration that will cost them somewhere between $80K and $600K depending on how deeply they embedded themselves.
What is the difference between TTFT and total generation - and why should you care?
Most teams measure latency as a single number. This is wrong. There are two numbers that matter, and they pull in opposite directions.
Time to First Token (TTFT) is how long a user waits before anything appears on screen. For chat interfaces, this is the number that determines whether your product feels fast or sluggish. Humans perceive anything under 400ms as instantaneous. Between 400ms and 1.2 seconds, they notice but tolerate. Above 1.2 seconds, they start wondering if the app is broken.
Total generation time is how long it takes to produce the full response. For batch processing, API-to-API workflows, and anything where the user is not watching tokens stream, this is the only number that matters.
Here is where it gets expensive: the flagship models from every provider optimize for quality at the cost of both metrics. Claude API (Opus) delivers remarkable reasoning but its TTFT regularly hits 2-4 seconds under load. OpenAI API (GPT-4o) is faster but still sits at 800ms-1.5s for TTFT in production. Meanwhile, Claude Haiku and GPT-4o-mini deliver sub-300ms TTFT at a fraction of the cost.
P50 latency tells you what most users experience. P99 tells you what your worst 1% experiences. A provider might advertise 500ms median latency, but if P99 is 8 seconds, one in every hundred requests feels broken.
When is batch API the obvious choice - and when is it a trap?
OpenAI API and Claude API both offer batch APIs at roughly 50% discount. The math seems obvious: if your workload can tolerate hours of delay, you cut your bill in half.
The trap: batch APIs create architectural dependencies on delayed processing. Your system now has two paths - real-time and batch. Every new feature requires asking "does this need to be real-time?" and maintaining two codepaths. When the business inevitably decides that the batch workflow needs to become real-time, you discover that your prompts were optimized for batch throughput, not streaming latency.
For most teams under $20K/month in API spend, the operational complexity outweighs the savings.
How much does vendor lock-in actually cost?
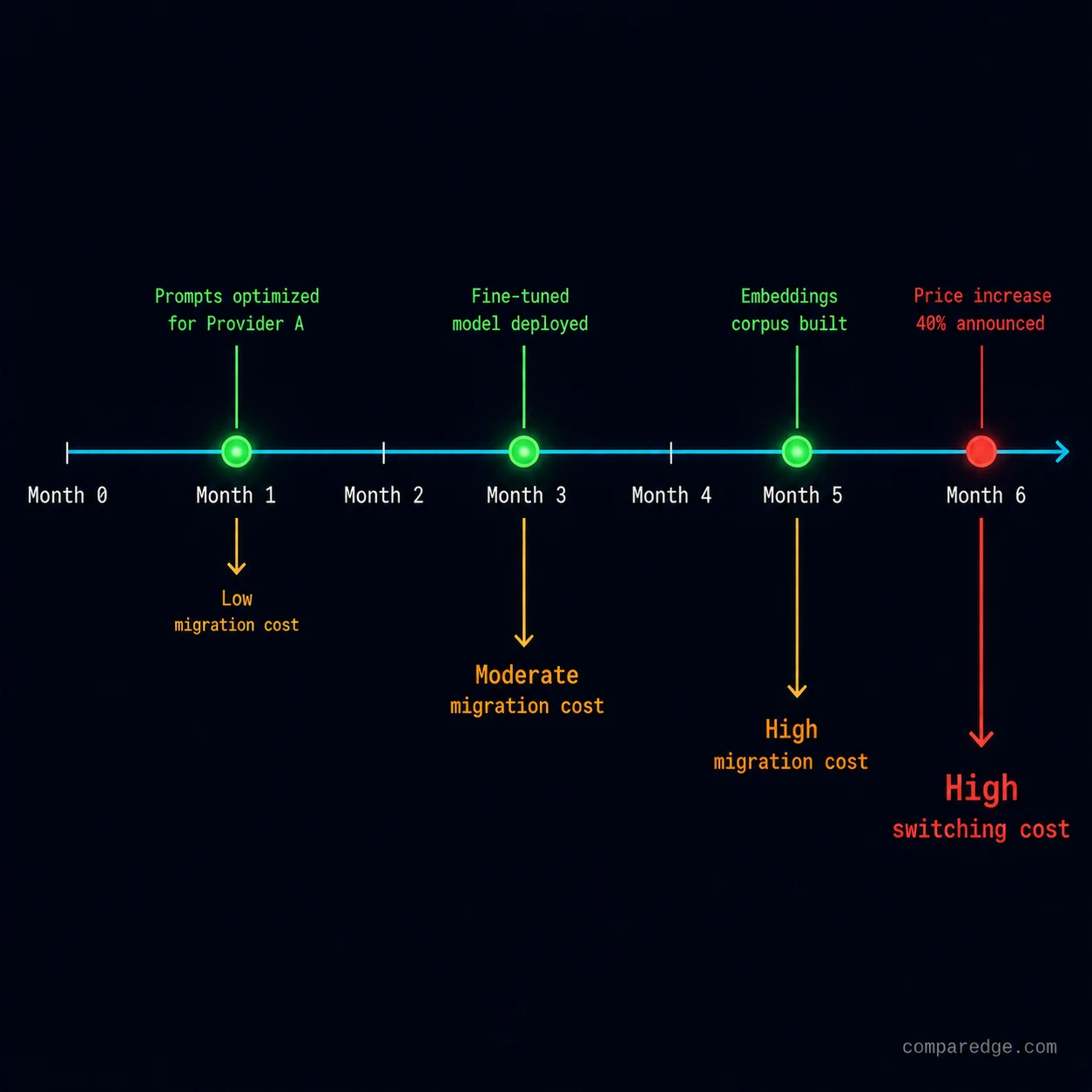
This is where the real money hides. Every team thinks they can switch providers easily. Almost none of them can. Let me break down the actual costs.
Prompt rewrites: 2-3 weeks of engineering time, minimum. Every model has different behaviors around formatting, instruction following, JSON output reliability, and edge cases. Your 35 production prompts were tuned through hundreds of iterations against a specific model's quirks. Budget $30K-80K in engineering time for a full prompt migration.
Fine-tuned models: completely non-portable. If you fine-tuned GPT-4 on your customer support data, that model exists only on OpenAI's infrastructure. Switching means re-fine-tuning from scratch on the new provider. Cost: $15K-50K for the fine-tuning runs alone.
Embeddings: the hidden killer. If you used OpenAI's text-embedding-3-large to embed 10 million documents, switching to a different embedding model means re-embedding every single document. Re-embedding 10M documents costs roughly $3K-8K in API fees and 2-4 weeks of pipeline work.
Total realistic lock-in cost for a medium-sized deployment: $150K-400K and 2-3 months of disrupted development. This is not a number most CTOs have in their risk registers.
Does a 1M token context window actually save you money?
Google AI Studio offers context windows up to 2M tokens. Anthropic pushes 200K. The marketing pitch is compelling: just dump your entire document corpus into context and ask questions. No RAG pipeline needed.
The mechanics say otherwise. Cost scales linearly with input tokens. Stuffing 500K tokens of context into every request at $3 per million input tokens means $1.50 per query just for the context. If your users ask 1,000 questions per day, that is $1,500 daily - $45K monthly - just for the context tokens, before you count output.
A well-built RAG pipeline retrieves 2-5 relevant chunks per query - maybe 2,000 tokens total. Same query costs $0.006 in input tokens. The infrastructure cost of running the RAG pipeline is real, but at scale it is a fraction of the long-context approach.
What happens to your GDPR compliance when you call an API endpoint in the US?
Data residency is the conversation that engineering teams avoid until legal forces it. When you send customer data to OpenAI API, that data is processed on servers primarily located in the United States. For EU customers covered by GDPR, this creates a data transfer issue.
Azure OpenAI offers EU-hosted endpoints in West Europe and France Central regions. This is currently the most straightforward path to GDPR-compliant GPT usage. But you are locked into Azure's pricing and deployment model.
Mistral, being a French company, offers EU-hosted inference - a genuine competitive advantage for European enterprises.
The practical risk: if a customer files a GDPR complaint about their data being processed outside the EU, the fine is up to 4% of annual global revenue. For a company doing $50M in revenue, that is a $2M exposure.
When is the flagship model the wrong choice for production?
For 70% of production workloads, the flagship model is overkill.
Claude API (Opus) is extraordinary at complex reasoning. It is also slow (2-4s TTFT), expensive ($15/M input, $75/M output), and wildly overpowered for tasks like "extract these 8 fields from an invoice" or "classify this support ticket into one of 12 categories."
One team spent $180K annually running Opus on a document classification pipeline. They switched to Haiku with a better prompt and got identical accuracy at $6K annually. The right architecture uses model routing: simple tasks go to small/fast models, complex tasks go to flagship models. This typically yields 60-80% cost reduction with negligible quality impact.
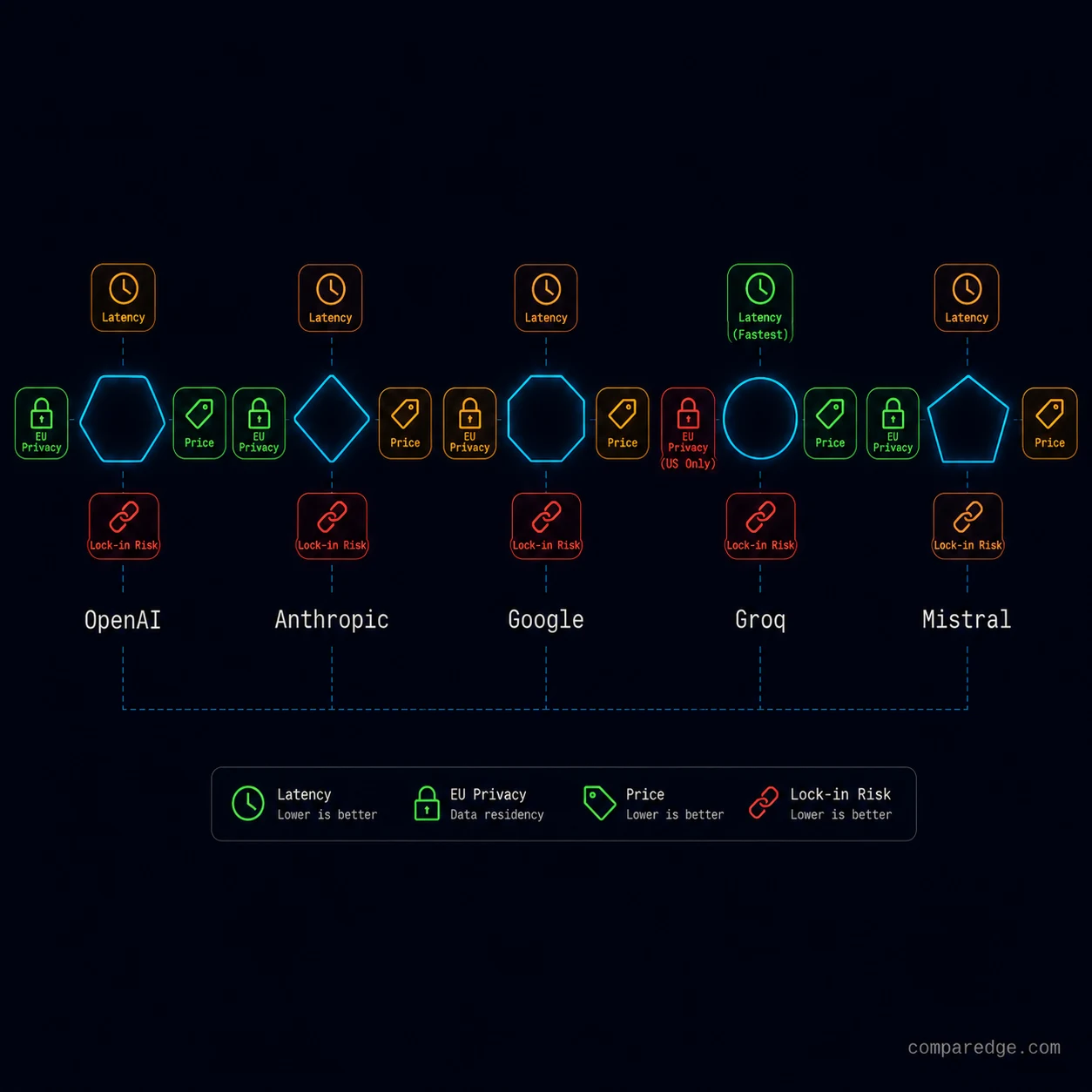
| Provider | P50 Latency (flagship) | Data Privacy (EU) | Price per 1M tokens (input/output) | Lock-in Risk |
|---|---|---|---|---|
| OpenAI API (GPT-4o) | 600-900ms TTFT | US default, Azure EU option | $2.50 / $10.00 | High - fine-tuning, embeddings ecosystem |
| Claude API (Sonnet) | 500-800ms TTFT | US/UK, Bedrock EU option | $3.00 / $15.00 | Medium - growing ecosystem, Voyage embeddings |
| Google AI Studio (Gemini Pro) | 400-700ms TTFT | Global, Vertex EU regions | $1.25 / $5.00 | Medium - tied to GCP ecosystem |
| Groq (Llama/Mixtral) | 100-200ms TTFT | US only | $0.05-0.27 / $0.05-0.27 | Low - runs open models |
| Mistral (Large) | 500-900ms TTFT | EU-hosted available | $2.00 / $6.00 | Low - open weights option |
What if your provider raises prices 40% with 30-day notice?
This is not hypothetical. OpenAI API has changed pricing multiple times. The 30-day notice period in most API terms of service means you have one month to absorb or react.
Your situation: 35 production prompts, one fine-tuned model, 10M documents embedded, and a team of 4 ML engineers who have spent the last year learning one provider's quirks.
Day 1-7: Panic. Finance calculates the new annual cost - it is $280K more than budgeted.
Day 8-14: You evaluate alternatives. Every alternative requires prompt rewrites (3 weeks), re-embedding (4 weeks), and re-fine-tuning (2 weeks). None of this fits in the remaining 16 days.
Day 15-30: You accept the price increase. You start a parallel migration project that will take 3 months and cost $200K in engineering time.
The mitigation is boring but effective: maintain prompt compatibility across at least two providers from day one. Use an abstraction layer (LiteLLM, OpenRouter, or a homegrown wrapper). Accept the 10-15% overhead of testing against two models.
What is the actual framework for choosing?
Stop thinking about which model is "best." Start thinking about these five questions in order:
- Where does your customer data need to physically reside? This eliminates options immediately.
- What is your P99 latency requirement? This determines your model size ceiling.
- What is your monthly budget, and what does the unit economics breakdown look like? This determines whether you need model routing.
- How much have you already invested in one ecosystem? This determines your realistic switching cost.
- What is your growth trajectory? A solution that works at 10K requests/day might not work at 1M.

The teams that get this right treat LLM APIs like they treat databases: as infrastructure that needs redundancy, monitoring, cost management, and a migration plan. The teams that get it wrong treat them like magic - pick the most powerful one and hope for the best.
Hope is not a strategy. Especially not at $47K per month.
Compare LLM API Providers
Before committing to a provider, compare latency benchmarks, pricing, and GDPR compliance options:
- OpenAI API vs Claude API - The two dominant enterprise LLM providers
- Groq vs OpenAI API - Ultra-low latency vs ecosystem depth
- Browse all LLM APIs and AI infrastructure on ComparEdge
API costs range from $0.05/M tokens (Groq) to $75/M tokens (Claude Opus). Model routing typically cuts production costs by 60-80% without quality loss.
Find the best tool for your use case: real pricing, user ratings, and feature comparisons for 495++ products.
Browse All Categories